
C语言快速入门
# 序言
C 语言是一种面向过程的计算机编程语言,多用于嵌入式开发(电路硬件编程)与系统底层编写, 比如我们常用的 Linux 系统,Windows 系统就是主要由 C 语言编写的。同时 c 语言也是最早出现的编程语 言之一,最早在 1972 年就已经被使用,并且直到现在它也是使用率最多的编程语言之一。
# 计算机的内存
代码本身存储在计算机的硬盘里,不管计算机开机还是关机,你写的程序的代码都是存在的,但是 一个程序要想运行起来就需要运行在计算机的内存里。
可以将计算机的内存想象成一个大的空间,这个空间中有各种各样的程序在运行着,并且每个程序 都会占用一定的空间,而所占空间的大小由程序本身所有的一些变量,函数等决定。
# 什么是编译器
我们的计算机只能够识别由 0 和 1 的二进制码,因此我们写出来的代码要想运行起来必须经过软件的 编译,将英文的编程语句转换为电脑能够识别的二进制码,不论哪种编程语言,最终都会经过编译转换 为计算机可识别的二进制码。** 将代码转换为二进制机器码的过程就叫做编译,负责进行转换的程序叫做 编译器。** 例如 gcc 编译器 等
# IDE (集成开发环境) 是什么
IDE 是 Intergreated Development Environment 的缩写,中文称为集成开发环境,是指辅助程序 员开发的应用软件。
我们已经知道,想要运行一个 C 语言程序必须有编译器,但是在实际开发过程中,除运行程序必须 的编译器之外,我们往往还需要很多其他的辅助工具,比如 语言编辑器、自动建立工具、除错器等等 。这些被打包在一起成为一个开发软件, 统一发布和安装,统称为集成开发环境(IDE)。比如我们使 用的 VS2010,devc++,CLion 等都是 IDE。
IDE 与编译器的区别
IDE 是编译器与其它各种开发工具的集合体。
面向过程思想
面向过程是一种以过程为中心的编程思想,其原理就是将问题分解成一个一个详细的步骤,然后通 过函数实现每一个步骤,并依次调用。 面向过程我们所关心的是解决一个问题的步骤,举个例子,汽车发动、汽车熄火,这是两个不同 的事件,对于面向过程而言,我们关心的是事件本身,因此我们会使用两个函数完成以上两个动作,然 后依次调用即可。
再比如 进入游戏,开始游戏,游戏结算,这是三个不同的事件,我们在玩游戏时只会关注这三个事 件,我们可以使用函数来表示这三个不同的动作,依次调用。
计算机基本快捷键的使用
- ctrl + 空格 /ctrl+shift : 快速切换中英文输入法
- Ctrl-X:剪切所选项并拷贝到剪贴板。
- Ctrl-C:将所选项拷贝到剪贴板。
- Ctrl-V:将剪贴板的内容粘贴到当前文稿或应用中。
- Ctrl-Z:撤销上一个命令。
- Ctrl-A:全选各项。
- Ctrl-S: 保存当前文件
- Ctrl-F:查找文稿中的项目或打开 “查找” 窗口。
- win+R: 唤起 “运行” 对话框,快速运行特定程序
- win+X: 唤起系统菜单
# 第一个程序(Hello World!)
1 |
|
# 程序解析
一个最基础的 C 语言程序由 预处理器指令,函数,变量,语句和表达式 以及 注释组成
接下来我们讲解一下上面这段程序:
- 程序的第一行 #include 是预处理器指令,告诉 C 编译器在实际编译之前要包含 stdio.h 文 件,可以将头文件理解为一个工具箱,在我们开始工作前,需要先拿好工具箱才能开始我们的 工作。
- 下一行 int main () 是主函数,程序从这里开始执行。
- 下一行 /…/ 将会被编译器忽略,不会执行,这里放置程序的注释内容。它们用来告诉读者 这个程序或者这些代码要做什么。
- 下一行 **printf (…)** 是 C 中另一个可用的函数,会在屏幕上显示消息 “Hello, World!”。
- 下一行 return 0; 终止 main () 函数,并返回值 0,表示程序完整地结束。
# 基本语法
分号:在 c 语言中,每个语句之后必须跟一个 英文分号表示一个语句的结束
注释:C 语言有两种注释方式,分别是 // 和上文那种,// 是单行注释,只会将一行标注为注释,而上文那种是多行注释。
1 | // 单行注释 // |
标识符:
C 标识符内不允许出现标点字符,比如 @、$ 和 %。C 语言是区分大小写的编程语言。因此,在 C 中, Manpower 和 manpower 是两个不同的标识符。
# 数据类型
# 基本类型
# int(整型)
可以用来声明一个整数变量
# short(短字节类型)
可以用来声明短整形(节约内存)
# long int(长字节类型)
当数据的大小超出 int 类型的上限时,可以使用 long int 甚至是 long long int 来扩大取值范围
# double 和 float(浮点类型)
double 和 float 用来表示浮点数(小数)
区别:
double 可以存储到小数点后 15 位,float 可以存储到小数点后 6 位
# char(字符类型)
char 是最小的基本类型,只占 1 个字节的存储空间,主要用来表示字符,例如‘a’,‘b’,‘c’,‘d’等。
值得注意的是,char 类型的‘1’和 int 类型的 1 是不一样的,在实际编写代码时需要注意。
# unsigned(无符号)修饰符
unsigned 可以用来修饰前面的数据类型,例如 unsigned int,unsigned char,unsigned double 等, 被 unsigned 修饰的数据类型其所占的存储空间大小不变,但是最大值会扩大为原来的 2 倍,最小值变为 0. 也就是说,一个数据类型被 unsigned 修饰以后,这个数据类型将变为无符号类型,也就是其不再有负 数值。
1 | int age = 20201022; |
相对于 unsigned,还有一个 signed 修饰符,signed 是有符号修饰符,但是我们一般省略他,c 语 言默认的数据类型都是有符号的
| 类型 | 储存空间大小 | 最小值 | 最大值 |
|---|---|---|---|
| char | (与 signed char 或 unsigned char 相同) | (与 signed char 或 unsigned char 相同) | (与 signed char 或 unsigned char 相同) |
| unsigned char | 1 个字节 | 0 | 255 |
| signed char | 1 个字节 | -128 | 127 |
| int | 2 个或 4 个字节 | -32 768 或 -2 147 483 684 | 32 768 或 2 147 483 684 |
| unsigned int | 2 个或 4 个字节 | 0 | 65 535 或 4 294 967 295 |
| short | 2 个字节 | -32 768 | 32 767 |
| unsigned short | 2 个字节 | 0 | 65 535 |
| long | 4 个字节 | -2 147 483 648 | 2 147 483 647 |
| unsigned long | 4 个字节 | 0 | 4 294 967 295 |
| long long(C99) | 8 个字节 | -9 223 372 036 854 755 808 | 9 223 372 036 854 755 808 |
| unsigned long long(C99) | 8 个字节 | 0 | 18 446 744 073 709 551 615 |
注:int 类型在 16 位系统中占 2 个字节,在 32 和 64 位系统中占 4 个字节
# 基本类型转换
# 1. 自动类型转换
当两个不同类型的变量进行运算时,编译器会自动进行类型转换,自动类型转换遵从以下规则:
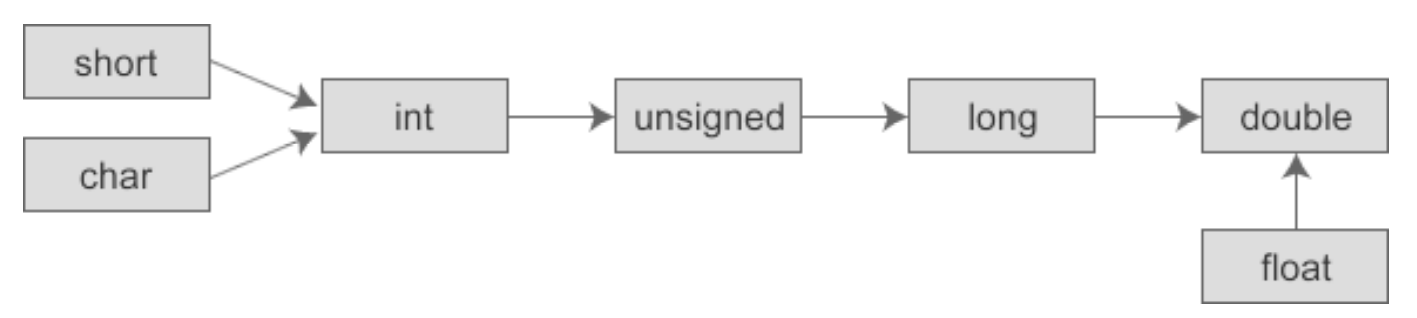
例如:
1 | int a = 1; |
在执行 a+b 运算的时候编译器会先把 int 类型的 a 转为 double 类型,然后再和 b 进行运算
# 2. 强制类型转换
1 | double a = 3.641593; |
注:在进行由高到低的强制类型转换时,数据会有部分丢失
强制类型转换是临时的,不会修改变量本来的类型
# 基本类型书写
整数
-
默认为 10 进制 ,10 ,20。
-
以 0 开头为 8 进制,012,024。
-
以 0b 开头为 2 进制,0b1010, 0b10100。
-
以 0x 开头为 16 进制,0xa,0x14。
小数
单精度常量(float):2.3f 。
双精度常量(double):2.3,默认为双精度。
字符型常量
用英文单引号括起来,只保存一个字符,‘a’、‘b’ 、’*’ ,还有转义字符 ‘\n’ 、’\t’。
字符串常量
用英文的双引号引起来 可以保存多个字符:“abc”。
# 变量
变量其实只不过是程序可操作的存储区的名称。C 中每个变量都有特定的类型,类型决定了变量存 储的大小和布局,该范围内的值都可以存储在内存中,运算符可应用于变量上。 例如
1 | int age = 5; |
这里的 age 就是一个变量,变量 age 的值为 5,而”age“叫做变量名。
同一类型的多个变量的声明之间可以用逗号隔开
1 | int i, j, k; |
# 变量的输入和输出
1.scanf
1 | // 输入char变量: |
2.printf
1 | // 输出char变量: |
| 符号 | 类型 | 说明 | 示例 | 结果 |
|---|---|---|---|---|
| x | unsigned int | 以十六进制小写输出 | printf("%x",11); | b |
| X | unsigned int | 以十六进制大写输出 | printf("%X",11); | B |
| o | unsigned int | 以八进制无符号整 S 输出 | printf( "%o”,100); | 144 |
| u | unsigned int | 以无符号整型输出 | printf( “%u,%u”,100u,100); | 100,100 |
| d、i | int | 以整型输出 | printf("%i,%d", 100,100); | 100,100 |
# 常量
常量是固定值,在程序执行期间不会改变。
常量可以是任何的基本数据类型,比如 int,double,char
# 常量的定义:
-
使用 #define 预处理器。
-
使用 const 关键字。 被 const 和 define 修饰的变量不可变
#define 预处理器
下面是使用 #define 预处理器定义常量的形式:
注意:define 定义之后不需要加分号
1 |
|
const 关键字
可以使用 const 前缀声明指定类型的常量,如下所示:
1 |
|
# 运算符
# 算术运算符
-
”+“运算符:把两个数相加
1
2
3
4int a = 2;
int b = 5;
int c = a + b;
printf("%d",c); // c = 7 -
”-“运算符:把两个数相减
1
2
3
4
5int a = 2;
int b = 5;
int c = a - b;
printf("%d",c); // c = -3 -
“*” 运算符:把两个数相乘
1
2
3
4int a = 2;
int b = 5;
int c = a * b;
printf("%d",c); // c = 10 -
“/” 运算符:把两个数相除,左边是被除数,右边的是除数(右边的数不能为 0):
1
2
3
4
5
6
7
8
9
10int a = 2;
int b = 5;
int c = a / b;
printf("%d",c); // c = 0
/*这里因为a,b,c都是int类型,a/b=0.4,所以会直接舍去后面的.4,只剩0*/
double d = 2.0;
double e = 3.0;
double f = e / d;
//double类型允许小数的存在,因此这里的f就是1.5了注意:C 语言不会对计算结果进行四舍五入,会直接全部舍去,比如 3.9,转为 int 类型的时候 就会变成 3
-
”%“:取余运算符,可以直接取整除之后的余数:
1 | int a = 2; |
- ”++“运算符:自增运算符,让变量的值加 1:
1 | int a = 2; |
a 与 a 的区别:
在进行 a++ 运算时,程序会先对 a 复制一次,然后让其 + 1,执行的操作类似 a = a + 1
在进行 ++a 运算时,程序会直接让 a+1
-
“–” 运算符:自减运算符,让变量的值 - 1:
与 ++ 运算符同理,a–运算会对 a 先复制一次,再让其 - 1,–a 会直接让其 - 1
1 | int a = 1; |
关系运算符
- == 运算符:
在 c 语言中 ” = “表示的是对一个变量进行赋值,而要想判断两个变量的值是否相同所用到的 是” == “运算符,该运算符返回的是一个真假值(在 c 语言中 1 表示真值,0 表示假值)。
1 | int a = 5,b = 5; |
- != 运算符:
这个运算符表示两个变量是否不同,返回值为真假值:
1 | int a = 5,b = 5; |
- > 运算符:
判断运算符左边的变量是否大于右边的变量:
1 | int a = 5,b = 5; |
- < 运算符:
判断运算符左边的变量是否小于右边的变量:
1 | int a = 4,b = 5; |
- >= 运算符:
判断运算符左边的变量是否大于等于右边的变量:
1 | int a = 5,b = 5; |
- <= 运算符:
判断运算符左边的变量是否小于等于右边的变量:
1 | int a = 4,b = 5; |
# 逻辑运算符
- && 运算符: 表示 “且”,如果左右两个操作全部为真,则该表达式返回真
1 | int a = 2,b = 3; |
- || 运算符: 表示 “或”,左右两个操作有一个为真,则该表达式为真
1 | int a = 2,b = 3; |
- ! 运算符: 表示 “非”,如果修饰的条件表达式为真,则该表达式为假,反之为真。
1 | int a = 2,b = 3; |
# 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,把右边操作数的值赋给左边操作数 | C = A + B 将把 A + B 的 值赋给 C |
| += | 加且赋值运算符,把右边操作数加上左边操作数的结果赋 值给左边操作数 | C += A 相当于 C = C + A |
| -= | 减且赋值运算符,把左边操作数减去右边操作数的结果赋 值给左边操作数 | C -= A 相当于 C = C - A |
| *= | 乘且赋值运算符,把右边操作数乘以左边操作数的结果赋 值给左边操作数 | C *= A 相当于 C = C * A |
| /= | 除且赋值运算符,把左边操作数除以右边操作数的结果赋 值给左边操作数 | C /= A 相当于 C = C / A |
| %= | 求模且赋值运算符,求两个操作数的模赋值给左边操作数 | C %= A 相当于 C = C % A |
1 | int a = 0; |
# 判断语句

判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需 的)和条件为假时要执行的语句(可选的)。
# if 语句
模式:
1 | if(条件语句) |
示例:
1 | int a = 0; |
一个 if 语句由一个条件语句后跟一个或多个语句组成
1 | int a = 0; |
# else 语句
当条件不满足 if 中的条件语句时会跳入 else 语句执行
1 | if(布尔表达式/条件语句) |

示例:
1 | int a = 3,b = 4; |
# else if 语句
当需要进行多次判断时,可以使用 else if 语句
1 | if(布尔表达式1/条件语句1) |
示例:
1 | int a = 3,b = 4; |
# switch case 语句
如果需要判断的语句很多的时候,if else 未免显得非常繁琐,因此我们可以使用效率更高,更加精 简的 switch case 语句。
1 | switch(变量){case 值1 :statement(s);//执行语句break; /* 可选的 */case 值2 :statement(s);//执行语句break; /* 可选的 *//* 可以有任意数量的 case 语句 */default : /* 可选的 如果匹配不成功就会跳到这个标签下面去执行这个标签下面的语句*/statement(s);} |
示例:
1 | int x = 5;switch(x){case 0:printf("x=0");//执行语句break; /* 可选的 */case 5:printf("x=5");//执行语句break; /* 可选的 *//* 可以有任意数量的 case 语句 */default : /* 可选的 如果匹配不成功就会跳到这个标签下面去执行这个标签下面的语句*/printf("no pattern");} |
switch 语句必须遵循下面的规则:
-
switch 语句中 case 后面是一个常量(不能为浮点数) 在一个 switch 中可以有任意数量的 case 语句。
-
case 后面的常量 必须与 switch 中的变量具有相同的数据类型。
-
当被测试的变量等于 case 中的常量时,case 后跟的语句将被执行,直到遇到 break 语句为 止。
-
当遇到 break 语句时,switch 终止,控制流将跳转到 switch 语句后的下一行。
-
不是每一个 case 都需要包含 break。如果 case 语句不包含 break,控制流将会继续后续的 case,直到遇到 break 为止。
-
一个 switch 语句可以有一个可选的 default,出现在 switch 的结尾。在上面所有的 case 都 不执行时执行。default 中的 break 语句不是必需的。
示例:
1 |
|
# 循环
当我们需要重复执行同一块代码时,我们可以使用循环操作来减少代码量。
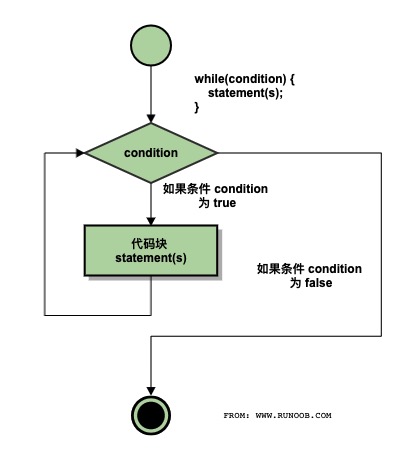
# 1.while 循环
1 | while(条件语句) |
示例:
1 | int n = 0; |
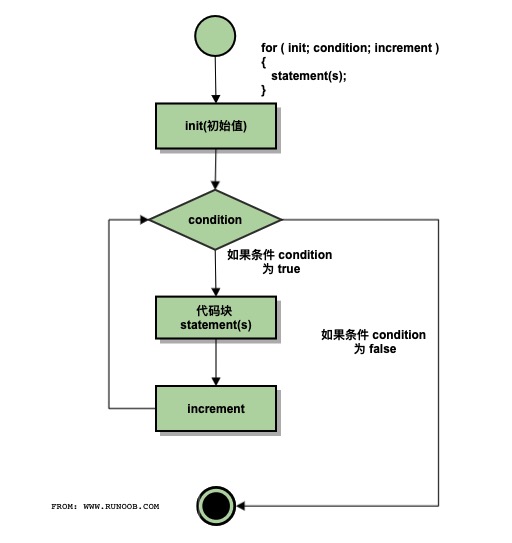
# 2.for 循环
#
1 | for ( init; condition; increment ) |
示例:
1 | for (int n = 0; n < 10; ++n) |
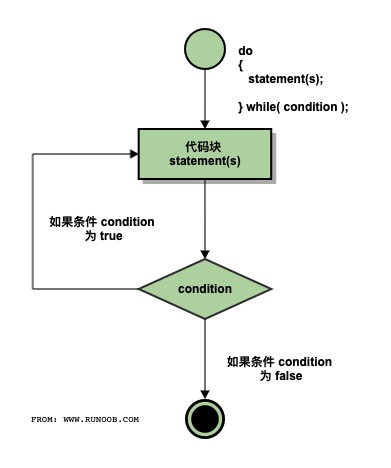
# 3.do…while 循环:
不像 for 和 while 循环,它们是在循环头部测试循环条件。在 C 语言中,do…while 循环是 在循环的尾部检查它的条件。
do…while 循环与 while 循环类似,但是 do…while 循环会确保至少执行一次循环。也就是 说,do…while 结构会先执行循环,后进行条件判断。
1 | do |
示例:
1 | int n = 0; |
# 函数
函数是一组一起执行一个任务的语句。每个 C 程序都至少有一个函数,即主函数 main () ,所有简 单的程序都可以定义其他额外的函数。
定义方法:
1 | 返回类型 函数名(参数){ |
** 返回类型:** 一个函数可以返回一个值。指函数返回的值的数据类型。有些函数执行所需的操作而不 返回值,在这种情况下,返回类型是 void。
1 | int max(int a,int b){ |
# 函数声明
1 | #include <stdio.h> |
# 数组
当我们需要声明或使用同一类型的多个变量时,一个个声明未免太过繁琐,我们可以使用数组来达 到这个目的。
数组是一个 固定大小 的 相同类型元素 的 顺序集合。
声明方式:
1 | 类型 数组名[数组大小]; |
示例:
1 | int array[10]; // 声明一个大小为10的int类型数组,它可以存储10个int类型的元素 |
# 初始化数组
1 | int array[5] = {0,1,2,3,4}; |
注意: 大括号 {} 之间的值的数目不能大于我们在数组声明时在方括号 [] 中指定的元素数目。
有时我们会开一个超级大的数组,这时使用大括号来进行初始化就非常麻烦了,因此我们结合之前 的循环操作来对数组进行初始化
1 | int array[5]; |
访问数组元素
数组元素可以通过数组名称加索引进行访问。元素的索引是放在方括号内,跟在数组名称的后边。 例如:
1 | int array[5] = {0,1,2,3,4}; |
注意:数组元素只被创建而没有被初始化的时候是不能进行正常访问的,只有数组中元素被赋值才 可以正常访问。
# 指针
# 使用指针
想要在函数中完成变量的交换,不被形参所限制。
指针可以达成我们的目的。
在程序运行时,变量被创建时, 变量都会被分配到一个内存位置。
内存位置可以通过 **& 运算符获取地址 **。
注意: 指针变量的类型必须要跟被取地址变量类型一致
# 怎么理解指针
让我们把 *p ,拆分成两部分去理解。
’p’ 部分 :是一个变量,能存储地址。
’*’ 部分 :获取变量 p 储存的地址,并找到该地址上存储的值。
运行上面的代码,输出 *p 的值就是 var 的值。
** 注意:** 多数时候指针初始化置 NULL 很有必要。
# 指针基本运算
指针就是地址,地址在内存中也是以数的形式存在,所以指针也能进行基本运算。
1 | int a; |
# 指向一维数组的指针
-
数组中的每个数据都会保存在一个储存单元里面,只要是储存单元就会有地址,所以就可以用 指针保存数组储存单元的地址。
为指针赋数组数据的地址
1 | int *p = NULL; |
可以使用指针操作一维数组
- 第一种
1 | int a[5]={0,1,2,3,4}; |
- 第二种
1 | int num[5] = {1,2,3,4,5}; |
# 指向二维数组的指针
跟一维数组相似
1 | int num[3][2] = {{1,2},{3,4},{5,6}}; |
- 注意: 不能为指针直接赋予二维数组的数组名,即上面的代码不能写成: int *p = num;
# 数组指针
顾名思义: 指向数组的指针
如果一个指针指向了数组,就称它为数组指针。c
1 | int a[4][3] = {{0,2,3},{1,5,6},{2,3,4},{7,8,9}}; |
在概念上的矩阵是像这种矩阵的样子:
1 | 0 2 3 |
但实际上它在内存中是链式存储的:
1 | 0 2 3 1 5 6 2 3 4 |
定义一个数组指针
1 | int (*p)[3] = a; |
括号里面的 * 代表 p 是一个指针,[3] 代表这个 指针 p 指向了类型为 int [3] 的数组
-
p 指向数组 a 的开头,就是指向数组的第 0 行元素,p + 1 指向数组的第一行元素
-
所以 *(p+1) 就表示数组的第一行元素的值,有多个数据
-
*(p+1) + 1 表示第一行的第一个数据的地址
# 二级指针
顾名思义: 指向指针的指针
假设有一个 int 类型的变量 a , p1 是指向 a 的指针变量, p2 又是指向 p1 的指针变量。
用代码形式展现就是:
1 | int a = 100; |
指针变量也是一种变量,也会占用存储空间,也可以使用 & 获取它的地址。C 语言不限制指针的级 数,每增加一级指针,在定义指针变量时就得增加一个星号。p1 是一级指针,指向普通类型的数据, 定义时有一个;p2 是二级指针,指向一级指针 p1,定义时有两个 *。
** 同理:** 指针可以有三级指针、四级指针等等。
# 指针在函数中的作用
指针作为函数的参数
写一个函数并调用,实现交换变量的值
1 |
|
运行上面的代码,a 和 b 的值并没有发生交换
# 形参(形式参数)
在函数定义中出现的参数,它没有数据,只能在函数被调用时接收传递进来的数据,所以称为形式参数。
# 实参(实际参数)
函数被调用时给出的参数包含了实实在在的数据,会被函数内部的代码使用,所以称为实际参数。 形参和实参的功能是传递数据,发生函数调用时,实参的值会传递给形参。
1 | void swap(int a,int b){ |
main 函数 中调用的 swap 函数 swap(a, b); 中的 a,b 是实参。
swap 函数 定义的 void swap(int a,int b) 中的 a,b 是形参。
在 c 语言中实参和形参之间的数据传输是单向的 “值传递” 方式,也就是实参可以影响形参,而形参不 能影响实参。指针变量作为参数也不例外,但是可以改变实参指针变量所指向的变量的值。
1 | //正确的变量交换代码 |
上面代码在调用 scanf 或者 swap 函数的时候,传入变量时,变量前都使用了 & 运算符
这两个函数通过传入的地址去改变了实参。
# 指针函数
C 语言允许函数的返回值是一个指针(地址),我们将这样的函数称为指针函数。
下面的例子定义了一个函数 strlong () ,用来返回两个字符串中较长的一个:
1 |
|
注意:函数运行结束后会销毁在它内部定义的所有局部数据,包括局部变量、局部数组和形式参数。
# 结构体
如果我们想存储多个学生的信息,比如身高、体重、学习成绩,等等。
在学结构体前,我们可以使用多个数组,用相同下标去存储一个学生的所有信息。
或者使用很多的变量,去储存信息,上述实现方法显得相当麻烦。
C 语言向我们提供了一种数据类型 :结构体(struct)。
1 | //结构体定义 |
这是一个结构体的定义,拆分看。
struct student: struct 是定义结构体必备的前缀。student 是结构体标签。 struct student 可 以像 int、double、float 作为定义变量的数据类型。
**{} 内的变量:** 结构体就像个模板,能规定好里面填什么变量。
**student1:** 定义 struct student 类型的变量 .
typedef
typedef 这是一个重命名的关键字
1 | //typedef + 数据类型 + 你想要重命名的英文 |
typedef 在这段代码中将 stu 等效成了 struct student ,而不是一个 struct student 类型的变量。
结构体变量的初始化
结构体也是一种数据类型,从某种程度上说与 int 等类似,属于同级,所以定义变量的方式也是一样的。
1 | truct Stu stu1,stu2; //这里定义了Stu类型的变量 |
结构体成员的赋值
结构体成员的获取形式为:
1 | 结构体变量名.成员名; |
示例:
1 | Stu stu1; |
# 结构体的使用
- 在结构体中使用数组
结构体中的成员变量可以是数组,没有什么特别的。
- 结构体与指针
结构体可以作为函数的参数传进子函数中,然后在子函数中使用.
下面是一个输出函数
Node 是一个结构体,print () 是一个子函数,这个子函数有一个 Node 类型的参数
1 | void print(Stu *stu) |
# 链表
结构体变量指针
- 结构体变量指向自身
1 | struct table{ |
-
指向其它结构变量
即将定义的两个结构体变量,比方说定义了 st1 和 st2 两个结构体变量,只需要将 st2 的地址 赋给 st1 的指针域,这样 st1 的指针就指向了 st2。
1 | struct table |
# 动态创建链表
-
构造一个结构类型,此结构类型必须包含至少一个成员指针,此指针要指向此结构类型
-
定义 3 个结构体类型的指针,按照用途可以命名为,p_head,p_rail,p_new
-
动态生成新的结点,为各成员变量赋值,最后加到链表当中。
-
动态创建的链表,没有一个单独的变量名去寻找到节点,全部都是由结构体中的 next 指针找 到下一个节点
1 | typedef struct node { |
定义结构体指针,不一定要在 main 函数中定义
1 | Node *p_head,*p_rail,*p_new ; |
# 使用 malloc 函数申请存储空间
1 | p_head = (Node*)malloc(sizeof(Node)); |
-
(struct node*) 强制类型转换
-
malloc () 申请空间函数
-
sizeof () 申请的大小函数 在使用完这个结构体以后可以使用函数
-
free () 将申请的空间释放。
示例:
构造结构体
1 | typedef struct node { |
# 链表操作
插入
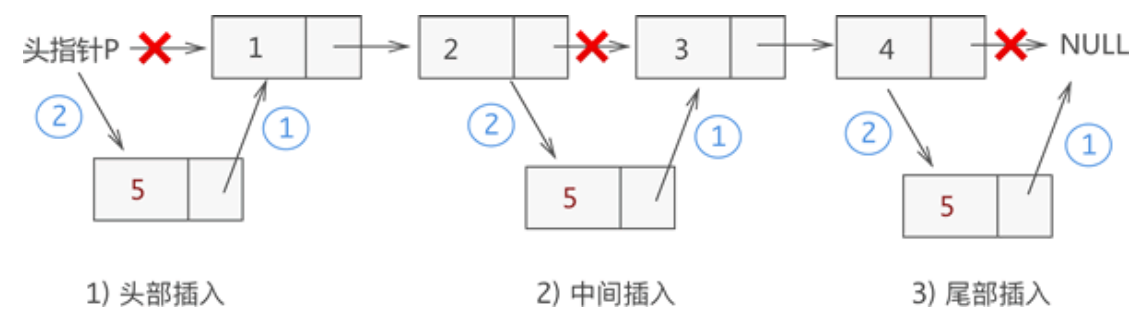
- 插入节点到头节点之前
1 | Node p_new = (Node *)malloc(sizeof(Node)); //创建新结点,并为其开辟空间 |
- 插入节点到链表中间
1 | Node *p_new = (Node *)malloc(sizeof(Node)); //创建新结点,并为其开辟空间 |
- 插入节点到末尾
1 | void insert(Node *p){ |
- 删除某一位置节点

1 | void del_list(struct node *p_head,int pos) |
 微信
微信 QQ
QQ 支付宝
支付宝




